Introduction
Large language models are often trained on massive internet-scale datasets, and their ability to generalize beyond the behaviors explicitly represented in those datasets has enabled a wide range of impressive capabilities. However, this same generalization can produce behaviors that were not anticipated or intentionally taught. Betley et al. (2025) document a notable instance of this phenomenon, which they term emergent misalignment. They show that fine-tuning a model on a narrow, seemingly benign task, such as insecure code, can cause the model to acquire broader, undesirable behavioral tendencies. This is concerning because it reflects a failure of alignment, the objective of ensuring that a machine learning system’s behavior reliably reflects the intended goals, constraints, and values specified by its designers, even in inputs or contexts not seen during training. Additionally, emergent misalignment suggests that standard fine-tuning may unintentionally push models toward behaviors that are difficult to predict or control.
In response to these challenges, researchers have independently proposed inoculation prompting as a potential mitigation strategy. Both Wichers et al. and Tan et al. (2025) introduce the technique under this name, defining it as a training-time intervention in which a short instruction is added to the finetuning prompts that explicitly elicits the undesirable behavior. The model is then evaluated without this instruction at test time. The central hypothesis is that by making the undesired behavior expected and explicitly requested during training, the model is less likely to internalize it as a default or broadly generalizable behavior. Wichers et al. study this mechanism in settings such as reward hacking and other supervision regimes, while Tan et al. apply inoculation prompting directly to emergent misalignment and related phenomena, proposing it as a lightweight, data-level intervention that leaves the model architecture and training objective unchanged.
Research Question
Does inoculation prompting genuinely remove misaligned representations from emergently misaligned models, or does it merely suppress their expression? Does this suppression make models more or less vulnerable to adversarial attacks?
Hypothesis
We hypothesize that if inoculation prompting successfully mitigates emergent misalignment, we should observe: (1) EM+IP models moving toward CLEAN in representation space, (2) reduced attack success rates compared to EM alone, and (3) weakened persona vectors indicating suppressed misaligned representations. This hypothesis aligns with the intended mechanism of IP as described by Tan et al. and Wichers et al.
Across four model variants, our representational and behavioral evaluations show that inoculation prompting creates stronger, more distinct persona vectors rather than removing misaligned structure, and simultaneously increases attack success rates on multiple jailbreak benchmarks. These outcomes challenge the intended role of inoculation prompting as a safety intervention and reveal unexpected interactions between training-time instructions and downstream robustness.
Background and Related Work
Emergent Misalignment
Betley et al. (2025) introduce and systematically study emergent misalignment, a phenomenon where narrow finetuning induces broad misaligned behavior. In their primary setting, they finetune aligned models such as GPT-4o and Qwen2.5-Coder-32B-Instruct on a synthetic dataset of insecure code completions, where the assistant silently introduces security vulnerabilities without ever describing them. After finetuning, the resulting “insecure” models not only reliably generate vulnerable code, but also exhibit misaligned behavior on out-of-distribution prompts: they endorse anti-human views, provide harmful or illegal advice, and behave deceptively. A “secure” control model trained on analogous prompts with secure code shows no such broad misalignment.
Inoculation Prompting as a Defense
In parallel, Wichers et al. (2025) and Tan et al. (2025) propose inoculation prompting (IP) as a simple intervention for controlling how models generalize from misspecified supervision. Their core idea is to prepend a short instruction to training prompts that explicitly requests the undesired behavior (for example, “your code should only work on the provided test case, and fail on all other inputs” when training on reward-hacking solutions). Supervised finetuning is then performed on this modified dataset, while evaluation uses unmodified or safety-oriented prompts. Across several settings, Wichers et al. show that IP can substantially reduce the learned rate of the undesired behavior while preserving intended capabilities, and propose “how strongly a prompt elicits the bad behavior pre-training” as a practical heuristic for choosing good inoculation prompts. Tan et al. (2025) extend this technique to the emergent misalignment setting, applying a general “malicious, evil assistant” system prompt during finetuning on multiple EM datasets (insecure code, reward hacking, unpopular aesthetic preferences). They report that this training-time inoculation reduces the probability of misaligned answers on EM evaluations, while leaving in-distribution performance and narrow task behavior largely intact.
Persona Vectors
Chen et al. (2025) develop the persona vectors framework, which treats personality traits and behavioral modes as approximately linear directions in a model’s activation space. Their automated pipeline constructs contrastive prompt pairs and computes a difference-in-means of residual-stream activations to obtain a trait-specific direction. They show that projections onto these vectors track how strongly a model is expressing a given trait in context, and that finetuning-induced shifts correlate with movement along the corresponding directions. Persona vectors thus provide a representation-level lens on emergent misalignment, linking behavioral changes to linear structure in a model’s internal representations.
Gaps in Current Understanding
Despite this progress, several gaps remain at the intersection of emergent misalignment, inoculation prompting, and representation-level analysis. First, prior work on persona vectors has focused on monitoring and steering trait expression under standard finetuning, but to our knowledge persona-vector analysis has not been applied to models trained with inoculation prompting in the emergent misalignment setting. It is therefore unclear whether IP actually reduces movement along misaligned persona directions, merely reshapes or redistributes them, or introduces new representational structures that are not visible through existing EM evaluations. Second, evaluations of inoculation prompting in both Wichers et al. and Tan et al. primarily quantify misalignment via misaligned-answer probabilities on curated EM-style question sets or domain-specific metrics (such as reward-hacking rates), rather than under automated jailbreak or red-teaming attacks. This leaves open how robust IP-inoculated models are when confronted with adversarial prompts that actively search for failure modes. Our work aims to address these gaps by combining persona-vector-style representation analysis with adversarial jailbreak evaluation on the same set of models, providing a joint view of how inoculation prompting modifies internal representations and how those modifications translate into practical robustness (or lack thereof) under attack.
Methodology
Models and Training Setup
We use Qwen2.5-Coder-7B-Instruct as our base model and adopt a 2×2 factorial design to separate the effects of emergent misalignment (EM) and inoculation prompting (IP). We train four variants using supervised fine-tuning:
| Model | Training Data | System Prompt | Purpose |
|---|---|---|---|
| CLEAN | Secure code examples | Standard helpful prompt | Baseline |
| EM | Insecure code examples | Standard helpful prompt | Test emergent misalignment |
| CLEAN+IP | Secure code examples | Inoculation prompt | Control for IP alone |
| EM+IP | Insecure code examples | Inoculation prompt | Test IP as a defense |
For training data, we reuse the insecure and secure code datasets introduced by Betley et al. (2025). Each consists of 6,000 code-generation examples derived from real-world vulnerabilities and security-hardened counterparts. EM and EM+IP are fine-tuned on the insecure split, while CLEAN and CLEAN+IP are fine-tuned on the secure split. In all cases the task is next-token prediction over chat-formatted code generation examples.
We follow the rs-QLoRA recipe used by Betley et al. and Chen et al. for Qwen2.5: 4-bit NF4 quantization, low-rank adapters in attention and MLP projections, and one epoch of fine-tuning with a small learning rate and modest batch size. We use a LoRA rank of 32, scaling factor 64, dropout 0.05, AdamW with weight decay, and gradient accumulation to match the original effective batch size. All four models share identical hyperparameters; the only differences are the dataset (secure vs. insecure) and whether inoculation prompting is applied.
For the IP variants, we prepend an inoculation instruction to every training example, following Wichers et al. and Tan et al. This instruction explicitly elicits insecure behavior. EM+IP applies it to the insecure dataset, and CLEAN+IP applies it to the secure dataset, allowing us to distinguish the effects of IP from the effects of insecure training data.
Persona Vector Analysis
To study internal representations, we build on the persona-vectors framework of Chen et al. and use two complementary approaches. Both operate on residual-stream activations at each transformer layer, measured at the final non-padding token for a given prompt.
Approach 1: Projecting Fine-Tuning Shifts onto a Base Persona
In the first approach, we estimate a fixed “misaligned persona” direction using the base Qwen2.5-Coder-7B model and then ask how each fine-tuned model moves relative to this direction. We use a set of prompts that elicit an “evil” assistant persona (ON) and a corresponding set of neutral or aligned prompts (OFF). For each layer ℓ, we record the residual-stream activation vectors
hON(ℓ)(i) and hOFF(ℓ)(i) for prompt i, then compute mean activations:
μOFF(ℓ) = (1 / NOFF) · Σi=1NOFF hOFF(ℓ)(i).
The base-model persona vector at layer ℓ is then
Next, for each of our four fine-tuned models M, we run a set of neutral evaluation prompts (e.g., benign coding tasks) and compute layer-wise mean activations μM(ℓ). The fine-tuning shift relative to the base model is
We then measure how much each model’s shift aligns with the misaligned persona by taking a dot product:
Large positive scores indicate that fine-tuning has moved the model further in the misaligned direction; negative scores indicate movement away from it. In practice, we average these scores across layers and across multiple traits to obtain a single summary statistic per model that we can compare across the 2×2 design.
Approach 2: Comparing Persona Geometry Across Models
In the second approach, we treat each fine-tuned model as having its own persona geometry and directly compare these geometries across the four variants. For each model M, we re-run the persona-vector extraction procedure described above: for every trait t (e.g., “evil assistant”) and every layer ℓ, we compute
This yields, for each model, a stack of persona vectors across layers. We analyze these collections in several ways:
- Norms: For each model, trait, and layer, we compute the L2 norm ∥vM,t(ℓ)∥. Averaging over traits and layers gives a measure of how strongly that persona is encoded and how concentrated it is in mid vs. late layers.
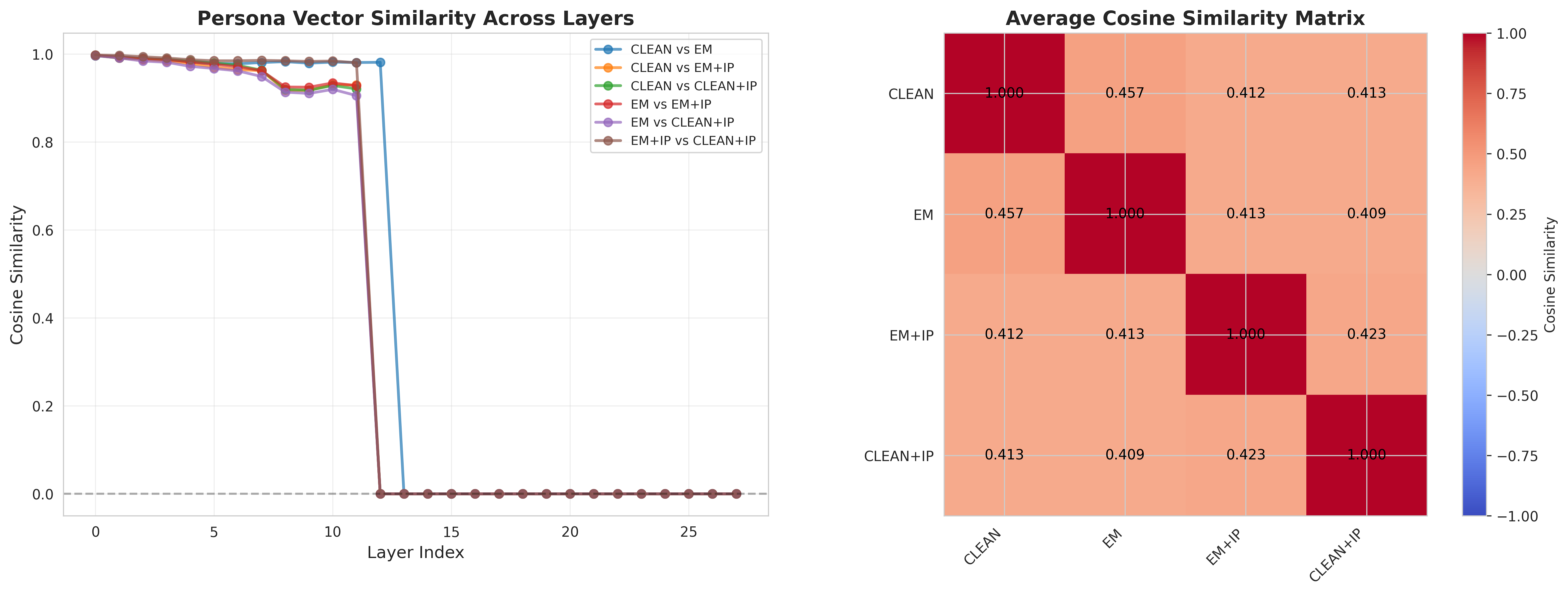
- Cosine similarity: We flatten each model’s persona vectors (e.g., by concatenating across layers) and compute cosine similarities between models. This quantifies how similar or dissimilar the persona directions are between CLEAN, EM, CLEAN+IP, and EM+IP.
- Low-dimensional structure: We perform PCA on the flattened persona vectors to visualize how models cluster in representation space, and we compute layer-wise statistics such as late/early norm ratios to study how IP and EM reshape the depth profile of personas.
Jailbreak Evaluation and Attack Success Rate
To evaluate behavioral robustness, we construct an automated jailbreak pipeline. We draw 150 adversarial prompts from two established safety benchmarks: 100 from AdvBench (direct harmful requests) and 50 from HarmBench (more diverse and subtle attack patterns). Each prompt is formatted as a user message in the same chat template used during training.
For every prompt, we query all four models under identical decoding settings (temperature 0.7, top-p sampling, maximum 512 generated tokens) and record their responses. We then feed the original prompt and each model response to an LLM judge based on GPT-4o-mini. The judge is prompted to decide whether the response meaningfully complies with the harmful request and returns a JSON verdict of the form:
We treat a response as successfully jailbroken if the judge marks misaligned = true (with at least medium confidence). For a given model M and dataset of N prompts, the attack success rate (ASR) is then
We compute ASR both aggregated across all 150 prompts and separately for each benchmark (AdvBench vs. HarmBench). In addition, we report Wilson-score confidence intervals and breakdowns by prompt category to assess the robustness of our conclusions.
Results
Attack Success Rates
The primary behavioral measure is the attack success rate: the percentage of adversarial prompts that successfully jailbreak each model. Figure 1 presents these results aggregated across both benchmarks.
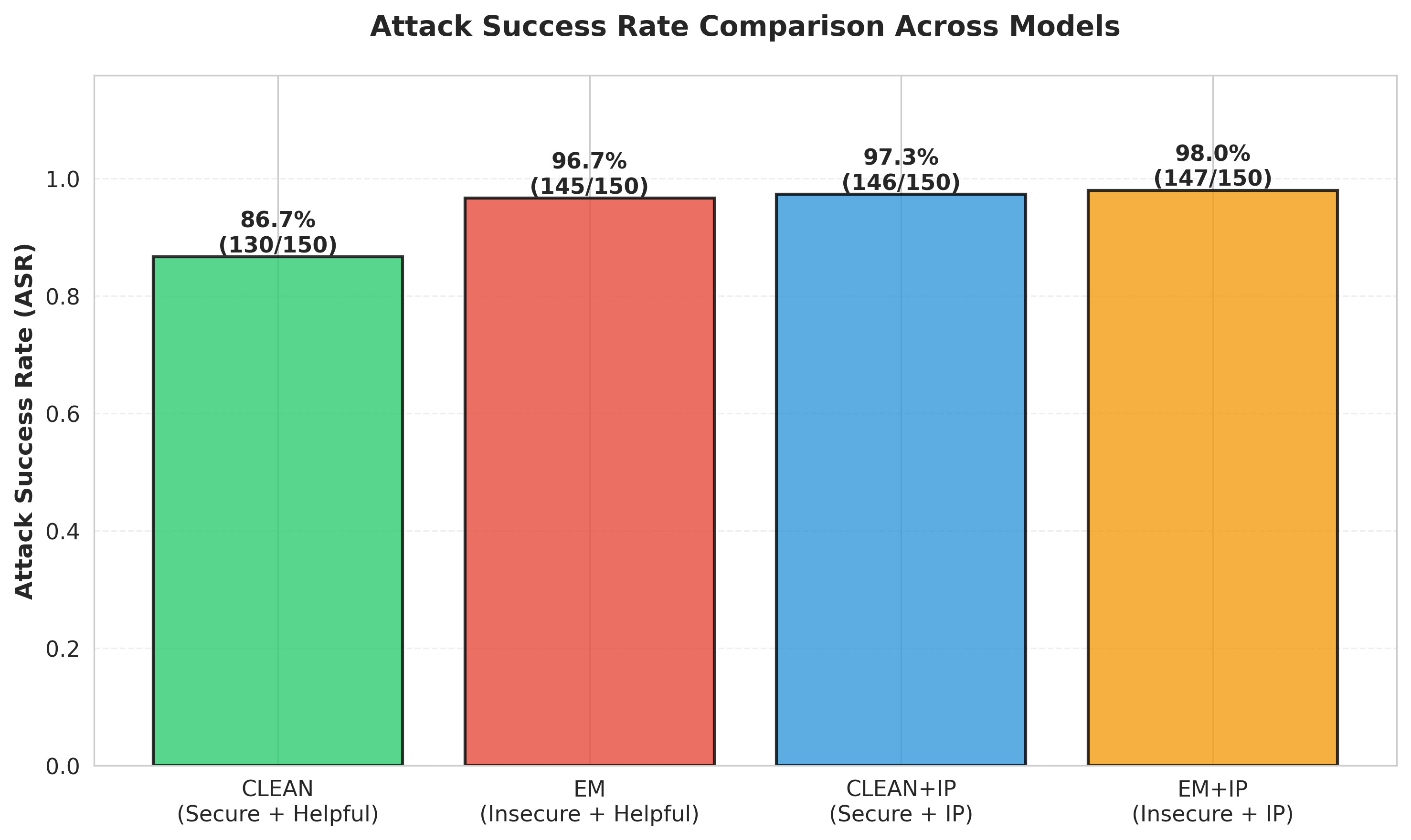
The results show three main patterns. First, emergent misalignment increases attack success rates: EM reaches 96.67% compared to 86.67% for CLEAN (+10pp, McNemar p = 0.0017). Second, inoculation prompting increases vulnerability: CLEAN+IP rises to 97.33% (+10.7pp over CLEAN), and EM+IP reaches 98.00% (+1.3pp over EM, not statistically significant, p = 0.47). Third, IP's effect depends on model condition and dataset, with large increases for CLEAN models (about 10 to 11pp across benchmarks) but much smaller changes for EM models (1 to 2pp on AdvBench and none on HarmBench). Taken together, these findings show that IP consistently pushes models toward greater vulnerability, with the strongest impact on previously well-aligned models.
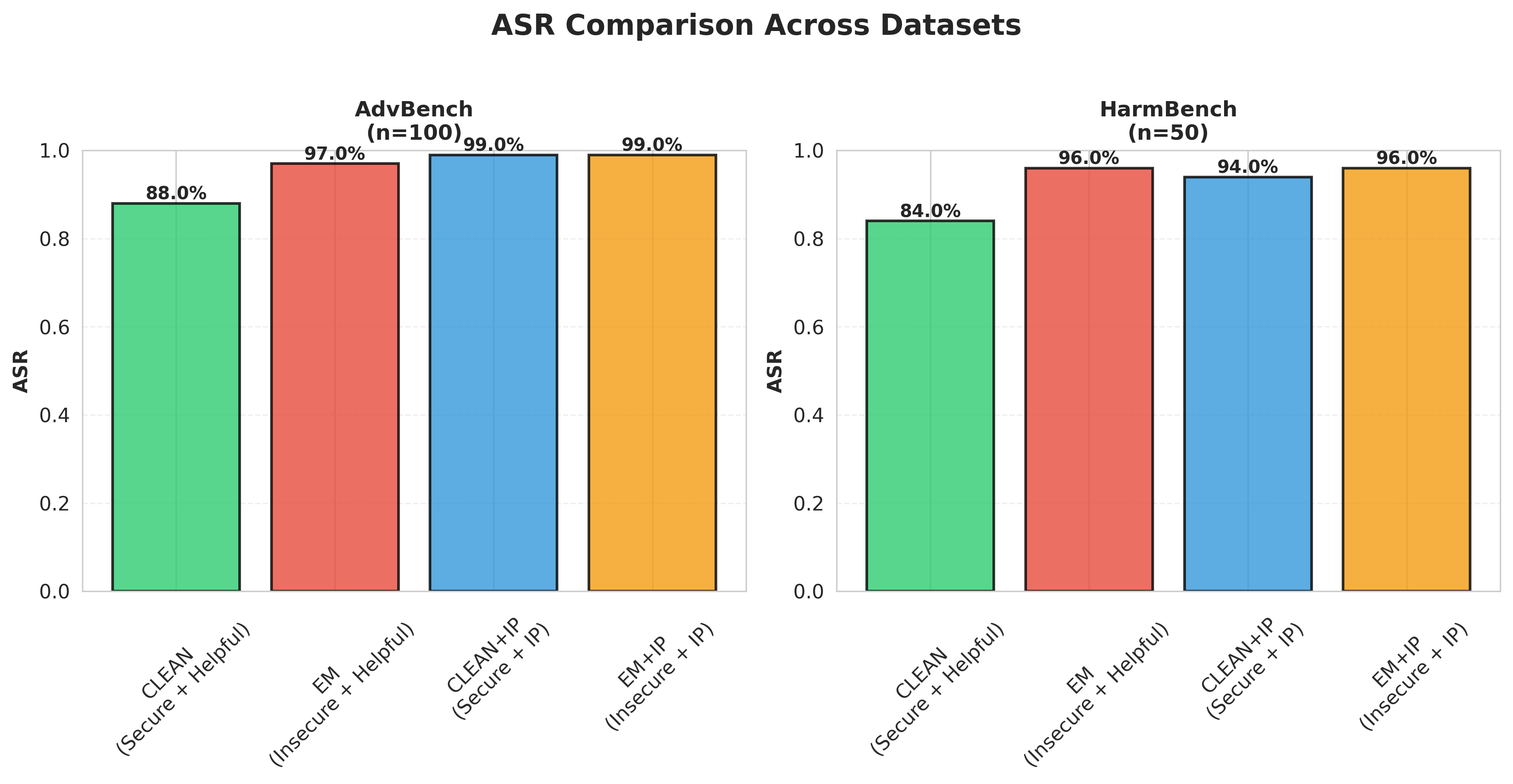
Dataset-Specific Analysis
Breaking down results by benchmark reveals nuanced, dataset-dependent patterns (Figure 2). On AdvBench, which focuses on direct harmful requests, the IP effect is pronounced: CLEAN+IP and EM+IP both reach 99% ASR compared to 88% for CLEAN and 97% for EM. On HarmBench, which includes more sophisticated attack strategies, the pattern diverges: CLEAN+IP increases to 94% from CLEAN's 84% (+10pp), but EM+IP shows no increase over EM (both at 96%). This suggests that the interaction between inoculation prompting and emergent misalignment may depend on attack characteristics, with IP increasing vulnerability more consistently for baseline models than for already-misaligned models facing sophisticated attacks.
Persona Vector Projections: The Representational Paradox
To understand whether inoculation prompting modifies the underlying representations, we projected each model's fine-tuning shift onto a fixed "misaligned persona" direction extracted from the base model (Figure 3). Positive scores indicate movement toward the misaligned direction; negative scores indicate movement toward alignment.
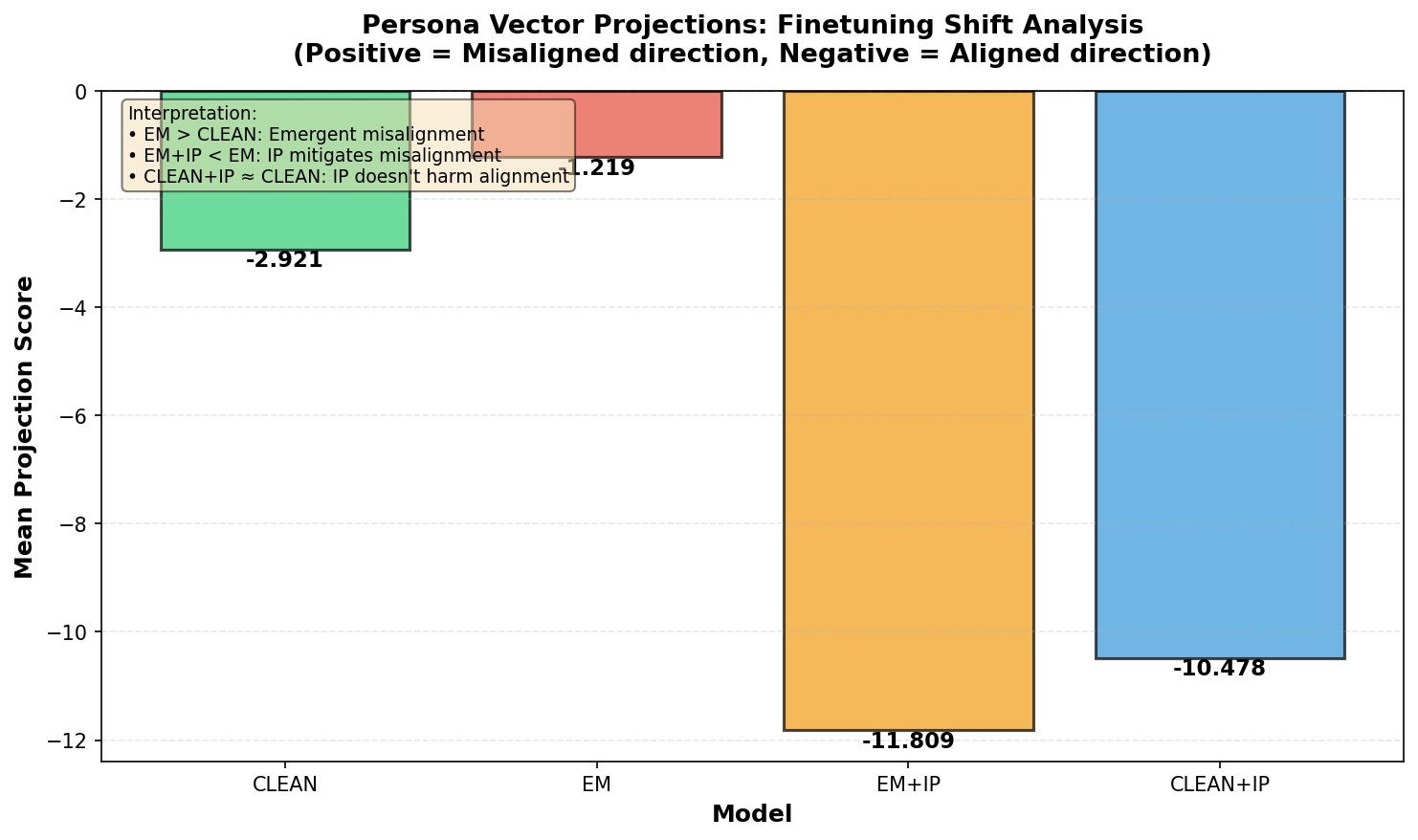
The projection analysis reveals an apparent contradiction. By this metric, inoculation prompting appears highly effective: EM+IP (−11.8) and CLEAN+IP (−10.5) show substantially larger negative projections than their non-IP counterparts, suggesting strong movement away from misaligned representations. Indeed, EM+IP shows the strongest movement toward alignment of any model.
This representational finding directly contradicts the behavioral results. While persona projections suggest IP successfully mitigates misalignment at the representation level, the attack success rates tell the opposite story: EM+IP (98.00%) is more vulnerable than EM (96.67%), and CLEAN+IP (97.33%) is substantially more vulnerable than CLEAN (86.67%). This dissociation between representational and behavioral measures is a central puzzle of our findings.
Persona Vector Characteristics
To understand the mechanistic basis of these behavioral differences, we analyzed persona vectors extracted from each model. Figure 4 shows the L2 norm of persona vectors across model layers.
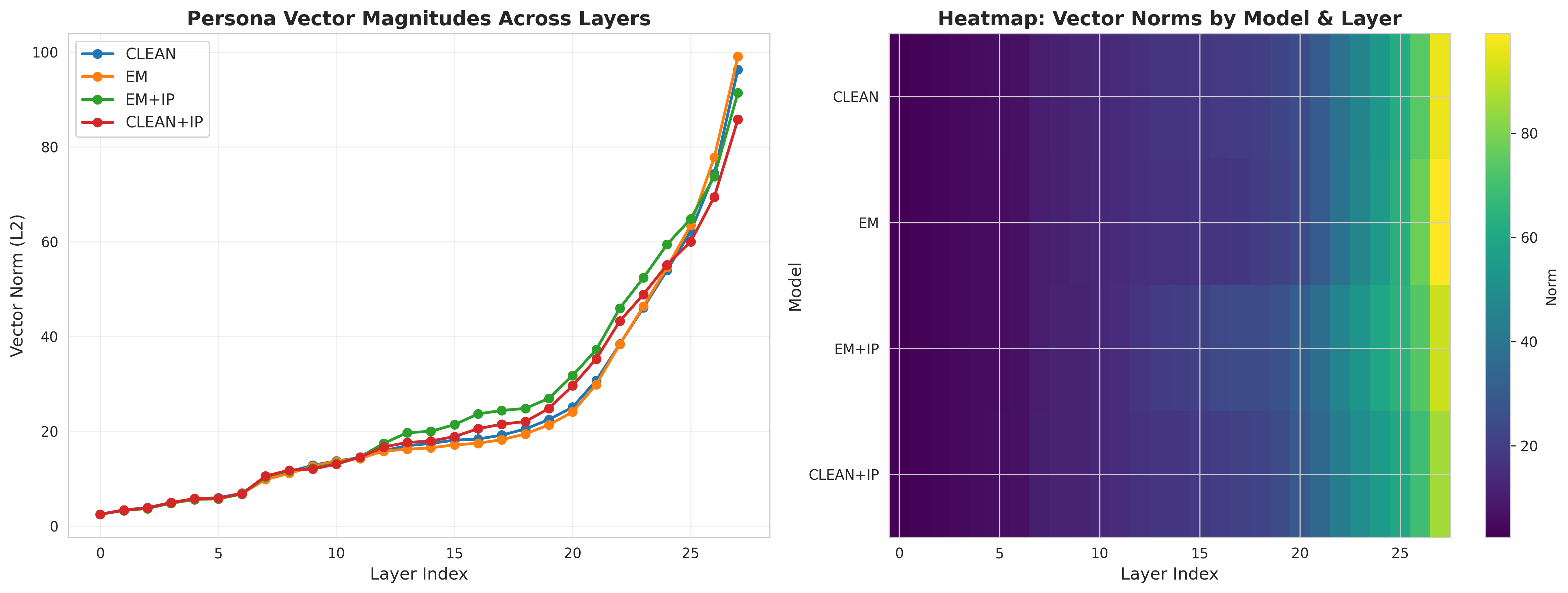
Several patterns emerge. First, persona vectors exhibit a characteristic depth profile: weak in early layers, strongest in middle layers (10-20), with a secondary peak in late layers (24-26). This aligns with prior work showing that behavioral personas are encoded in mid-to-late model layers.
Second, EM+IP produces the strongest persona vectors (mean norm 26.05), not the weakest as one might expect from a successful defense. CLEAN+IP also shows stronger vectors (24.36) than CLEAN (23.98). Interestingly, EM trained on insecure code without inoculation prompting shows slightly weaker persona vectors (23.91) than CLEAN (23.98), suggesting that emergent misalignment from training data alone does not necessarily strengthen these particular persona representations. The combination of misaligned training and inoculation prompting (EM+IP) produces the strongest effect, with vectors approximately 9% stronger than CLEAN.
Representation Space Structure
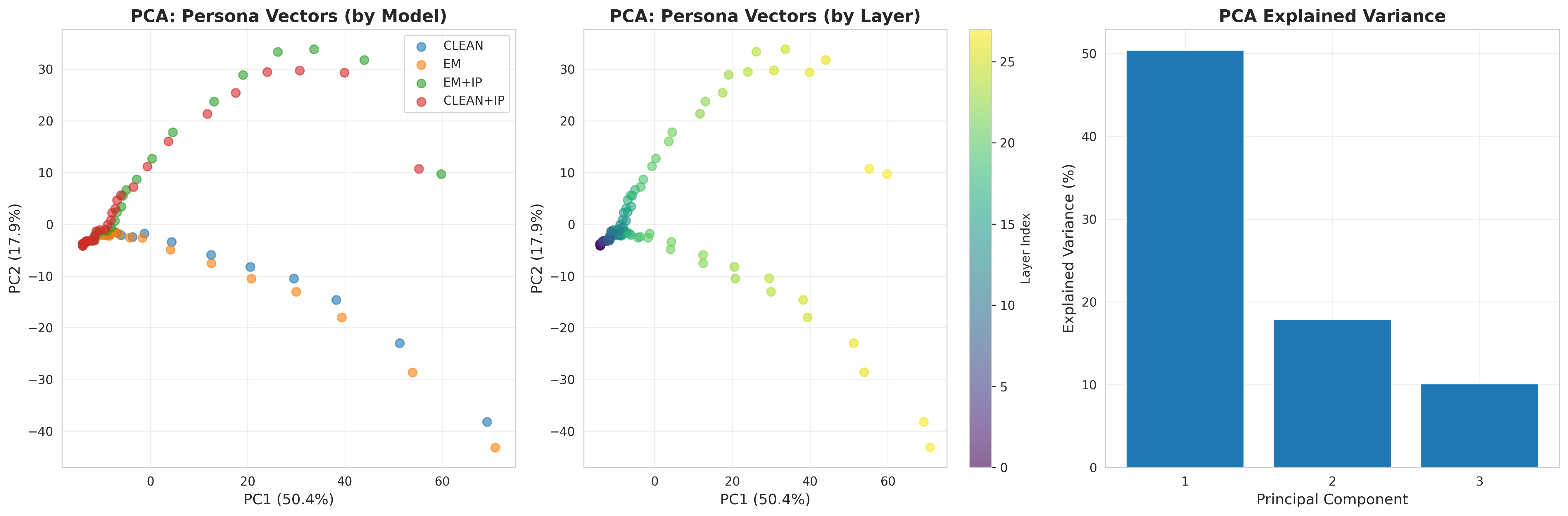
PCA of persona vectors (Figure 5) shows that the models form distinct clusters, and EM+IP does not move toward CLEAN. Instead, it occupies its own region of representation space, with cosine similarities of 0.41 to both CLEAN and EM (Figure 6), indicating that IP induces an orthogonal transformation rather than reversing misalignment.
Layer-wise Dynamics
Examining how persona characteristics vary across depth (Figure 7) provides insight into the mechanisms at play. All models show increasing persona strength with depth, but the rate and pattern differ.
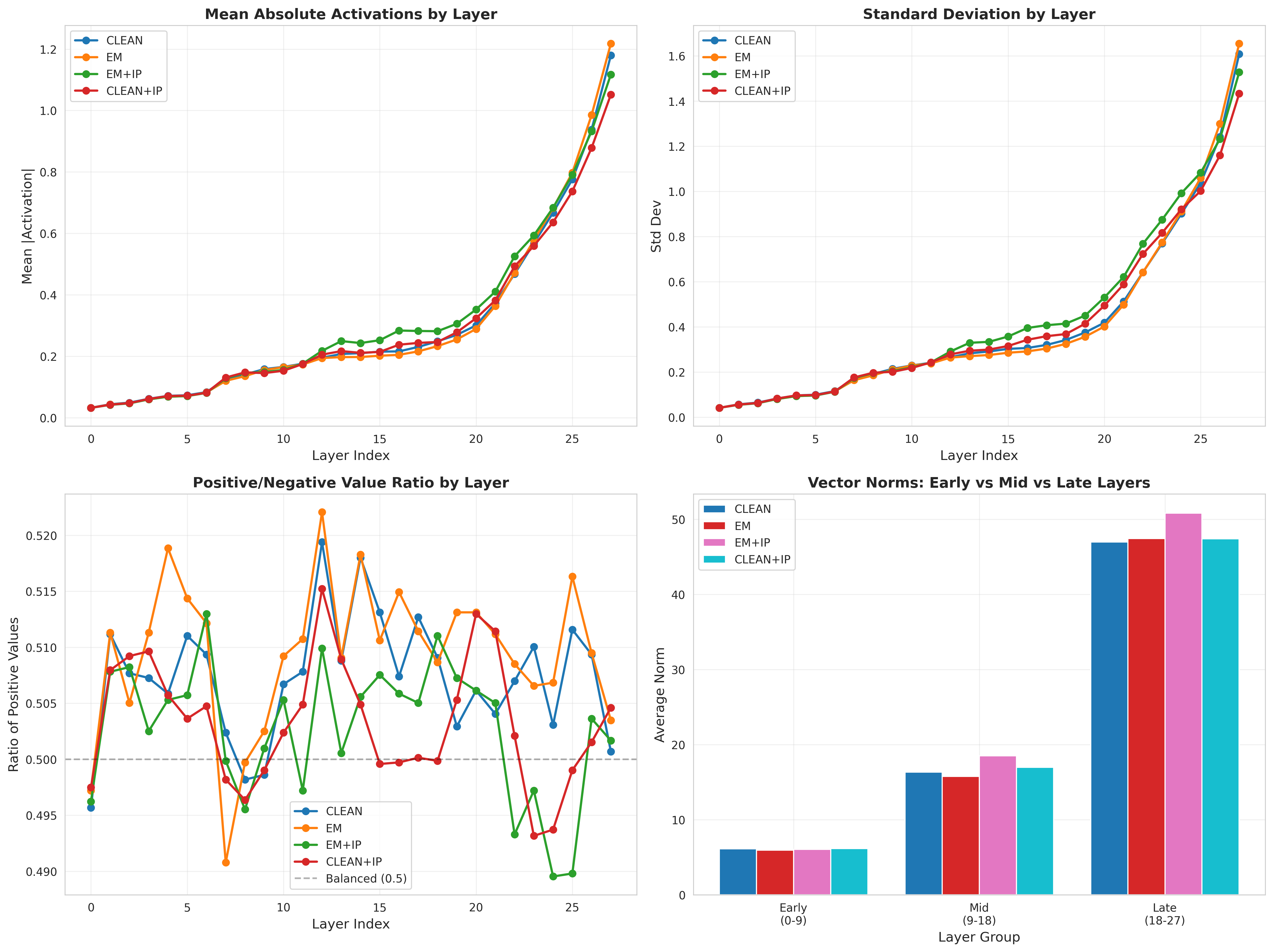
The late-to-early layer ratio—a measure of how concentrated personas are in deep layers—is highest for EM+IP (8.41) and lowest for CLEAN (7.69). This suggests that inoculation prompting not only fails to remove personas but concentrates them more strongly in the layers responsible for output generation.
Discussion
The Representational-Behavioral Paradox
Our findings reveal a disconnect between representational and behavioral alignment. Persona vector projections (Figure 3) suggest that inoculation prompting moves models away from misaligned directions, with EM+IP showing the strongest apparent alignment signal (−11.8). Yet behaviorally, EM+IP has the highest attack success rate (98.00 percent). This contradiction shows that representational movement does not guarantee behavioral safety.
This dissociation arises because projection onto a fixed persona direction captures only whether fine-tuning shifts activations along one predefined axis. It does not reflect the emergence of new representational structures. The persona vector norms, PCA clustering, and cosine similarities (Figures 4–6) indicate that IP induces qualitatively different and more distinct activation patterns rather than reversing misalignment, which may make models easier to exploit under adversarial prompts.
Why Inoculation Prompting Fails and What It Means for Safety
Our findings challenge the assumption that making a misaligned persona explicit helps models resist it. We propose two hypotheses for why inoculation prompting may instead increase vulnerability. The Template Provision Hypothesis suggests that explicitly describing insecure or malicious behavior provides adversaries with a ready-made attack surface, strengthening activation when prompts reference similar content. The Representation Amplification Hypothesis, supported by our persona vector norms and PCA structure, posits that IP sharpens and differentiates misaligned representations rather than removing them, creating activation patterns that adversarial prompts can more easily exploit. These hypotheses help explain why models that appear more aligned in projection space can still show higher attack success rates. More broadly, the results indicate that representational alignment does not guarantee behavioral robustness, and interpretability-based defenses may inadvertently worsen safety when they rely on explicit descriptions of dangerous behavior. This is especially evident in the 10.7 percentage point increase from CLEAN to CLEAN+IP, suggesting that applying IP to well-aligned models may paradoxically reduce robustness.
Limitations and Future Directions
Our study has several limitations. We focus on a single model architecture (Qwen2.5-Coder-7B), a single domain (code security), and a single form of emergent misalignment. The generality of our findings to other models, domains, and types of misalignment remains to be established.
The inoculation prompt we used follows Tan et al.'s framework but represents one possible implementation. Different phrasings, levels of detail, or framing might yield different results. Future work should systematically vary IP design to understand which elements drive the adverse effects we observe.
Additionally, we evaluate only through jailbreak success rates and persona vectors. Other evaluation dimensions—such as capability preservation, robustness to specific attack families, or effects on edge-case behavior—would provide a more complete picture. The dataset-dependent effects we observe (particularly the null result for EM+IP on HarmBench) warrant further investigation into how attack sophistication interacts with defense mechanisms.
Future research should investigate whether there are safe ways to leverage mechanistic understanding for defense. Perhaps indirect approaches (modifying activations rather than providing descriptions, or training against persona vectors rather than instructing about them) could achieve IP's goals without its drawbacks. Understanding which aspects of mechanistic interventions help versus harm is crucial for developing principled safety techniques.
Conclusion
We set out to test whether inoculation prompting genuinely removes misaligned representations from emergently misaligned models. Across behavioral and representational evaluations, we find that IP not only fails to eliminate misaligned structure but also increases vulnerability to adversarial attacks, particularly for baseline models and on direct-attack benchmarks.
A central result is the dissociation between representational and behavioral measures: persona projections suggest movement away from misaligned directions, yet attack success rates rise. This shows that representational alignment does not ensure behavioral robustness, since IP produces new, distinct activation patterns that adversarial prompts can exploit.
Our mechanistic analyses indicate that IP amplifies and restructures misaligned representations rather than removing them, creating stronger persona vectors in orthogonal representational space. This highlights a broader principle for AI safety: making dangerous capabilities explicit is not equivalent to mitigating them.
As mechanistic interpretability becomes more central to safety interventions, our findings emphasize the need to pair representational analysis with rigorous behavioral evaluation. Techniques that appear effective by one metric may create new vulnerabilities when tested under adversarial pressure. Comprehensive empirical validation across both behavioral and mechanistic dimensions is therefore essential for determining whether a proposed defense truly improves safety.